

A Scrumptious Error at Scientific Reports
What does a dog's breakfast taste like?

Ah, Scientific Reports.
Springer Nature’s open access journal — one of the world’s most cited! — has been openly assessed1 as sometimes containing work “so seriously flawed that it is not credible that it underwent any meaningful form of peer review.”
We’ve been down the road of Bad Science Papers with Scientific Reports here on no bs. before. The famous case of the Autism Bicycle is probably fresh in people’s minds. The crowd loves a poorly-generated AI figure.
This case isn’t quite as visually striking, but it is interesting.
This really is a scrumptious case.
[Something about the word “scrumptious” immediately reminds me of Tim Curry. So let’s not keep you waiting. I see you shiver with antici…]

I was recently looking through some of my correspondence with various publishers about investigations and integrity issues that I’d flagged and decided to check out Scientific Reports in 2026. How’s it looking?
For an answer, I went to the fabulous “Problematic Paper Screener” (PPS) and did all the hackerman stuff to get it to spit out papers that might be worrying.2 A very recent publication about using AI for lung detection caught my eye.
I’ve long been interested in how AI might be used in diagnoses and it’s one area that seems ripe for, at the very least, AI assistance. I’d been looking into this a few years back when I was with the ABC. There’s a ton of reports and studies out there about its use.
The PPS flagged a paper titled “LungGANDetectAI: a GAN-augmented and attention-guided deep learning framework for accurate and explainable lung cancer detection”.
The PPS suggested it have a human look over it because it contained a couple of tortured phrases.
But this paper is so much more than a few tortured phrases. It’s a veritable buffet of mangled script; a dog’s breakfast of weird inconsistencies, formatting errors and one absolutely delectable mistake.
Starting on that last point: In the “Related work” section of the paper, which is a long and winding literature review that has hallmarks of using some sort of text spinner that replaces words or perhaps being aided by LLM/generative AI, we get this delicious sentence:
“Using a state-of-the-art technique for lung cancer detection (CCDC-HNN), Wankhade and Vigneshwari demonstrated a correct and real-time identification of lung cancer. It combines RNN and 3D-CNN models for improved feature extraction and photo classification in CT scans. The results show that both the test and training samples achieve a scrumptiously high accuracy of 95%.”
Oooh. I see!
Scrumptiously high accuracy!
According to data listed on Dimensions.ai, this is the only time the word “scrumptiously” appears in more than 280,0003 papers from Scientific Reports. That, in itself, is a really scrumptious find. These authors can lay claim to introducing a three-syllable banger into the Scientific Reports lexicon.
But this might be a fleeting win. The first to achieve the record; the first to lose the record…
Hot Hot Heat
The strangest inconsistency in the paper seems to be Figure 15, which shows “heatmaps” using a technique called Grad-CAM.

I am not the person that should be interrogating these but I know who might be able to! People who create tutorials for Grad-CAM.
An article at Edge Impulse shows how Grad-CAM can help visualise neural network decisions. You can see the images in the piece paint a rather interesting picture of how these will sometimes look:

The heatmaps with these cars and trucks are displaying what the “AI” is “seeing” [shudder] to make decisions and classify things, as I understand it. But these heatmaps look nothing like the maps produced in the Scientific Reports paper. Those heatmaps look like pure noise, right?
And they contain the labelling as part of the imagery, too. Which I find a bit strange!
One of the Edge Impulse authors, Louis Moreau, told me that “I have no medical expertise so I cannot really help here but having the label on the image is clearly a red flag for me.”
The text of the paper is also rather jumbled around this figure, as you can see below:
Grad-CAM Visualisations for a Subset of CTExamples (a) Grad-CAM visualisations (displayed in Fig. 15) for a set of CT examples. As is usual (a), the lung tissue is activated diffusely and corresponds to the absence of lesions. In the benign case (b), we observe localised nodular regions but no aggressive spreading elsewhere. In the malignant case (c), however, the activations would be located around the cloudy nodules and hyperdense margins, a distinguishing feature for breast diagnostics, reaffirming the clinical relevance of the explanation results.
In the routine scan, Grad-CAM activations are sparsely distributed across the lung parenchyma, demonstrating normal lungs without suspicious lesions. In the benign case, overlaid regions: green ellipses connected by horizontal lines, correspond to nodular shapes (red dots) over localised areas, indicating a precise target of attention over low-attack tissue densities.
It points to “a distinguishing feature for breast diagnostics” even though this is a paper about lung cancer. It also confuses itself with the location of the (a) descriptor. Instead of saying “normal”, it flips the word to “usual”, which feels like a tell-tale sign of LLM use or paraphrasing tools. Whatever the case, the paragraphs end up being nonsensical when you look at the Figure 15 images anyway.
The heat maps are overlayed on imagery that still contains labels. This appears to be the exact imagery in Fig. 4, which is fine, but wouldn’t you use the Grad-CAM just on your CT scans… and not your CT scans plus the arbitrary container you house them in?
Moreau also notes that when the labels appear and are run through Grad-CAM, typically the heatmaps light up around the labels, an unusual bias that infects these models.The second paragraph discusses where these “activations” are distributed. If you think there’s a major difference in distribution of activation across the three states then… you’re certainly more adept at this than I. There are no points on the image that seem to be focused on by the AI at all? If I understand this correctly, then that’s uh… undermining the whole idea of the AI being used to adequately detect cancers?
I posted these concerns on PubPeer and alerted the Springer Nature integrity team to them on February 18.
Rafal Marszalek, Chief Editor of Scientific Reports told no breakthroughs:
“Thank you for bringing this to our attention. We have now begun a thorough investigation into the paper with support from the Springer Nature Research Integrity Group. We have added an Editor's Note to alert readers to concerns with the paper and we will take further editorial action as appropriate.”
Which, yes, it did:
Marszalek continued:
“We recognise the concerns surrounding the use of AI and are continually working to strengthen our processes to ensure the reliability of the content we publish. While we already have a range of checks in place, Scientific Reports introduced an additional workflow in January 2026 to help identify potentially problematic submissions more effectively. These enhanced checks were not available when this paper underwent editorial review.”
Here’s one I prepared earlier:
The dataset used in this paper is something called the “IQ-OTH/NCCD lung cancer” dataset. This is a dataset of more than 1,000 images of lungs, taken from 110 patients in the Iraq-Oncology Teaching Hospital/National Center for Cancer Diseases.
I plugged that into Google and the first result I got was another paper, also in Scientific Reports, published in July of last year:
Developing an innovative lung cancer detection model for accurate diagnosis in AI healthcare systems
This one isn’t quite as scrumptious, but it does feel like it would benefit from a lot of editing. Like a half-eaten chocolate cake on a hot day, it’s just all over the place; it’s really messy.
For instance…
In the methodology section, it says that “Model cross-validation was performed using the CT-Scan image data set, which has 364 images altogether, of which 238 are cancerous and 238 are non-cancerous.”
The math ain’t mathing.
Or there’s the line “The ability of [lung cancer screening] imaging to detect underdiagnosed viruses in [lung cancer screening] populations is a significant and as of yet unrealized advantage” which may be true in some cases, but seems wildly out of place in a research piece about lung cancer.
There’s also “Various approaches are employed to identify lung cancer; however, these techniques are not suitable for detecting lung cancer” which I’ve spent the last 10 minutes trying to decode. What techniques! What approaches!?
Also, in Table 2, there are multiple unusual signs. Someone forgot to hit a % perhaps, but other values are at 00.78 or three decimal places.
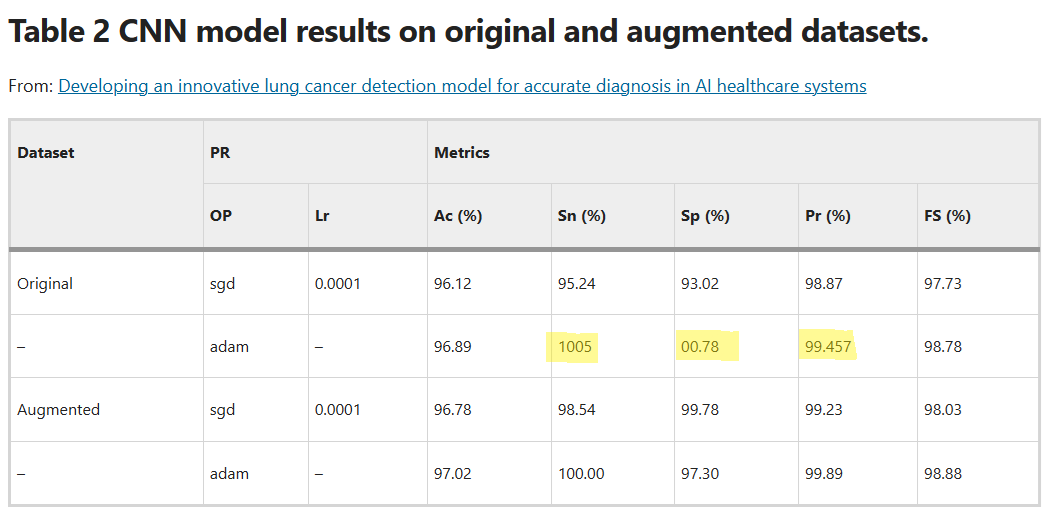
These errors concern me that this paper, too, might be problematic. It doesn’t contain scrumptiously, sadly, and this one also was published before the Scientific Reports “workflow” changes that Marszalek spoke to above. There’s a need to look a little closer at it, particularly for those who are in the AI / CT scanning sort of realm…
That’s all on this delicious little error for this week. I am throwing down a challenge to all scientists who read this: If you’re going to publish soon, get the word scrumptiously in your paper. You’ll get at least one reader (me).
See you next week!
Some scribbles
— In my other beat, video games, I wrote about the future of Freeplay, one of (if not the) oldest independent video game festival in the world at The Saturday Paper.
— The tip jar is open at Ko-fi, if this newsletter pleases your eyes. There’s a couple of longer investigations I am doing, so I may soon switch to paywalls for those. I dunno. I want to get off Substack though. Current tips stand at $115.00 Australian Dollarydoos.
— Read this piece at Nature with interest: It describes how USAID cuts are hindering science journalism. What goes unsaid in the piece: Springer Nature made hundreds of millions of dollars in profit. If science journalism matters to scientific publishers (and it should!) then a relatively small investment from the publisher would go an extremely long way. Just imagining what even $1m AUD would do for science (and investigative) journalism in low and middle income nations almost makes me cry.
— Still experimenting with when to send the newsletter. Lots of options, this time we’re going Monday afternoon Australia time, so Europeans get this one early Monday morning. Let me know if you like the timing!
This from Dorothy Bishop and co-signed by some of the big names in scientific sleuthing back in 2024…
No hacking required, just a few different filters.
Correction immediately post-publication! 4:07a.m. UTC: Originally I’d written “160,000”, but the Dimensions.ai search shows 282,689 papers at Scientific Reports, so not sure where I took that number from…